
Postgres Live search
How to Build a Trigram Live Search with PostgreSQL, Django REST Framework, and React
Checkout the gitrepo here (will upload in a few days!)
In this blog post, I will walk you through building a quick and powerful feature you can easily add to your full stack web applications. This search allows you to quickly filter through a database in real time, giving immediate feedback as you type (without spamming your endpoint). In this case, I'm going to build a database of dog breeds and utilize a fuzzy search to return results.
Project Overview
The application architecture:
- Backend: Django REST Framework with PostgreSQL database
- Frontend: React with Vite, Tailwind CSS for styling
- Search: Fuzzy search using PostgreSQL trigram similarity
- Real-time: Live search that updates as you type
How Trigram Search Works
There are a few different approaches to live searches, each with their own pros and cons and ideal use cases.
- Tries: You can use a data structure called a trie. Tries are a tree structure that are built with prefixes, allowing you to narrow down the list of possibilities while you type. This is often used by search engines for autocompletes because it greatly reduces the time complexity of the search (). It won't be ideal for this particular use case where we want to return results even if we don't have an exact match.
- Levenshtein search: This search is a fuzzy search, but unlike trigram it doesn't take advantage of indexing, reducing memory usage but increasing the time it takes to return results. This is more often used in spell checkers where the fuzzy algorithm is more important and the algorithm can be slower without affecting user experience.
- Elasticsearch: A distributed search and analytics engine that provides powerful full-text search capabilities. While very powerful, it adds significant complexity and infrastructure overhead compared to simpler solutions. See my other article for a good use case in ELK stack.
- Trigram search: This search, combined with GIN (Generalized Inverted Index) indexes, takes advantage of precomputed indexes to quickly provide results for LIKE matches. This is ideal for our use case because we want to optimize the speed of returned results.
Let's take a closer look at Trigram:
Let's say we have a database of names set up with these columns:
| id | name |
|---|---|
| 1 | "Brendan" |
| 2 | "Pat" |
| ... | ... |
| 400 | "Brandon" |
| 401 | "Braydon" |
| ... | ... |
| 577 | "Brennen" |
| ... | ... |
The way our precomputed indexes work is by generating all the 3-letter combinations (padded with spaces on the edges) and pointing to the valid rows.
So for "Brendan" the trigram indexes would include:
__B
_Br
bre
ren
end
nda
dan
an_
n__We can think of this index like a dictionary pointing to the IDs of the matches in our database:
dict["__B"] = {1, 400, 401, 577}
dict["_Br"] = {1, 400, 401, 577}
dict["bre"] = {1, 577}
dict["ren"] = {1, 577}
dict["end"] = {1}
dict["nda"] = {1}
dict["dan"] = {1}
dict["an_"] = {1, 400}
dict["n__"] = {1, 400, 401, 577}As you can see, as the user types these different three-letter combinations, different results show up. This, combined with other fuzzy or LIKE searches, results in much faster lookups () at the expense of RAM memory.
Backend Setup
1. Create Django Project and Virtual Environment
# Create virtual environment
python3 -m venv django_backend
source django_backend/bin/activate
# Install dependencies
pip install Django djangorestframework django-cors-headers psycopg2-binary
# Create Django project
cd django_backend
django-admin startproject live_search .2. Create Django App
python manage.py startapp dogsNote
I love this feature of Django it really helps keep things organized which I'll comment on later.
3. Configure Settings
In live_search/settings.py, we added:
- REST Framework to
INSTALLED_APPS:
INSTALLED_APPS = [
# ... default apps
"rest_framework",
"dogs",
"corsheaders",
]- CORS Middleware to handle cross-origin requests:
MIDDLEWARE = [
# ... other middleware
"corsheaders.middleware.CorsMiddleware",
]
CORS_ALLOW_ALL_ORIGINS = TrueNote
Don't hate on CORS. I see this on Twitter all the time and it annoys me so much. CORS is so simple and it has a purpose—learn how to use it, and do not set ALL origins and push that to prod. 🤦
- PostgreSQL Database Configuration:
DATABASES = {
"default": {
"ENGINE": "django.db.backends.postgresql",
"NAME": os.environ.get("DB_NAME", "some_postgres"),
"USER": os.environ.get("DB_USER", "postgres"),
"PASSWORD": os.environ.get("DB_PASSWORD", "mysecretpassword"),
"HOST": os.environ.get("DB_HOST", "localhost"),
"PORT": os.environ.get("DB_PORT", "5432").split(":")[-1],
}
}4. Setup PostgreSQL Running on Docker
Normally I would use GCP Cloud SQL or the equivalent AWS or Azure databases to run this for prod, but while developing an example and messing around, a local Docker image is ideal (I need to justify my bad decisions M4 MacBook somehow).
- Pull the image from Docker Hub:
docker pull postgresI'm not going to pretend that I know everything about Docker. For some reason, I ran into storage issues. I had another large Docker image and I could not get this to run without deleting all my other Docker containers using
docker system prune -a. In general I find Docker to be quite finicky and often requires purges and restarts. IDK?! Please enlighten me if you know why.You need to start the container, then use the GUI to check if it's actually running. Note the flag
-p 5432:5432 \which exposes the port to the OS so you can actually access it.
docker run -d \
--name some-postgres \
-e POSTGRES_PASSWORD=mysecretpassword \
-e POSTGRES_DB=some_postgres \
-p 5432:5432 \
postgres5. Create the DogBreed Model
In dogs/models.py, we created a comprehensive model for dog breeds:
class DogBreed(models.Model):
SIZE_CHOICES = [
("tiny", "Tiny (under 10 lbs)"),
("small", "Small (10-25 lbs)"),
("medium", "Medium (25-50 lbs)"),
("large", "Large (50-80 lbs)"),
("xlarge", "Extra Large (80+ lbs)"),
]
name = models.CharField(max_length=100, unique=True)
description = models.TextField(blank=True)
temperament = models.CharField(max_length=500)
size = models.CharField(max_length=20, choices=SIZE_CHOICES)
weight_min = models.IntegerField()
weight_max = models.IntegerField()
# ... many more fields for comprehensive breed data6. Create and Run Migrations
python manage.py makemigrations #this makes the ORM migration file
python manage.py migrate #this actually runs the SQL queries and updates the databaseAn interesting side note: if you want to better understand how the Django ORM (Object Relational Model) works under the hood, you can see the generated migration files under dogs > migrations > 0001_initial.py. This is the file Django created after running makemigrations. Occasionally you might have to edit these by hand, but if you use startapp and organize your project properly, everything should run smoothly without ever needing to manually touch these. I also find it interesting to look under the hood—ORMs still work by running optimized SQL. You can see the query by running python manage.py sqlmigrate dogs 0001.
(django_backend) ➜ django_backend python manage.py sqlmigrate dogs 0001
BEGIN;
--
-- Create model DogBreed
--
CREATE TABLE "dogs_dogbreed" ("id" bigint NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, "name" varchar(100) NOT NULL UNIQUE, "description" text NOT NULL, "temperament" varchar(500) NOT NULL, "size" varchar(20) NOT NULL, "weight_min" integer NOT NULL, "weight_max" integer NOT NULL, "height_min" integer NULL, "height_max" integer NULL, "life_expectancy_min" integer NOT NULL, "life_expectancy_max" integer NOT NULL, "origin" varchar(100) NOT NULL, "exercise_needs" varchar(20) NOT NULL, "grooming_needs" varchar(20) NOT NULL, "good_with_children" boolean NOT NULL, "good_with_other_dogs" boolean NOT NULL, "good_with_strangers" boolean NOT NULL, "trainability" integer NOT NULL, "energy_level" integer NOT NULL, "barking_tendency" integer NOT NULL, "created_at" timestamp with time zone NOT NULL, "updated_at" timestamp with time zone NOT NULL);
CREATE INDEX "dogs_dogbreed_name_9f30f02a_like" ON "dogs_dogbreed" ("name" varchar_pattern_ops);
COMMIT;7. Create Serializer
In dogs/serializers.py:
class DogBreedSerializer(serializers.ModelSerializer):
class Meta:
model = DogBreed
fields = "__all__"8. Create API View with Fuzzy Search
In dogs/views.py, we implemented a search endpoint using PostgreSQL's trigram similarity for fuzzy matching:
from django.contrib.postgres.search import TrigramSimilarity
from django.db.models import Q
@api_view(["GET"])
def list_breeds(request):
search_query = request.query_params.get("search", None)
if search_query:
# Use trigram similarity for fuzzy search
breeds = (
DogBreed.objects.annotate(
name_similarity=TrigramSimilarity("name", search_query),
)
.filter(Q(name_similarity__gt=0.2))
.order_by("-name_similarity", "name")
)
else:
breeds = DogBreed.objects.all()
serializer = DogBreedSerializer(breeds, many=True)
return Response(serializer.data)Key Features:
- Uses
TrigramSimilarityfor fuzzy matching (handles typos and partial matches) - Filters results with similarity > 0.2 (adjustable threshold)
- Orders by similarity score, then alphabetically
8. Configure URLs
In dogs/urls.py:
urlpatterns = [
path("breeds/", views.list_breeds, name="list_breeds"),
]In live_search/urls.py:
urlpatterns = [
path("admin/", admin.site.urls),
path("api/", include("dogs.urls")),
]9. Enable PostgreSQL Trigram Extension
For fuzzy search to work, we need to enable the pg_trgm extension:
# Connect to PostgreSQL
psql -U postgres -d some_postgresYou can do this either through the GUI:
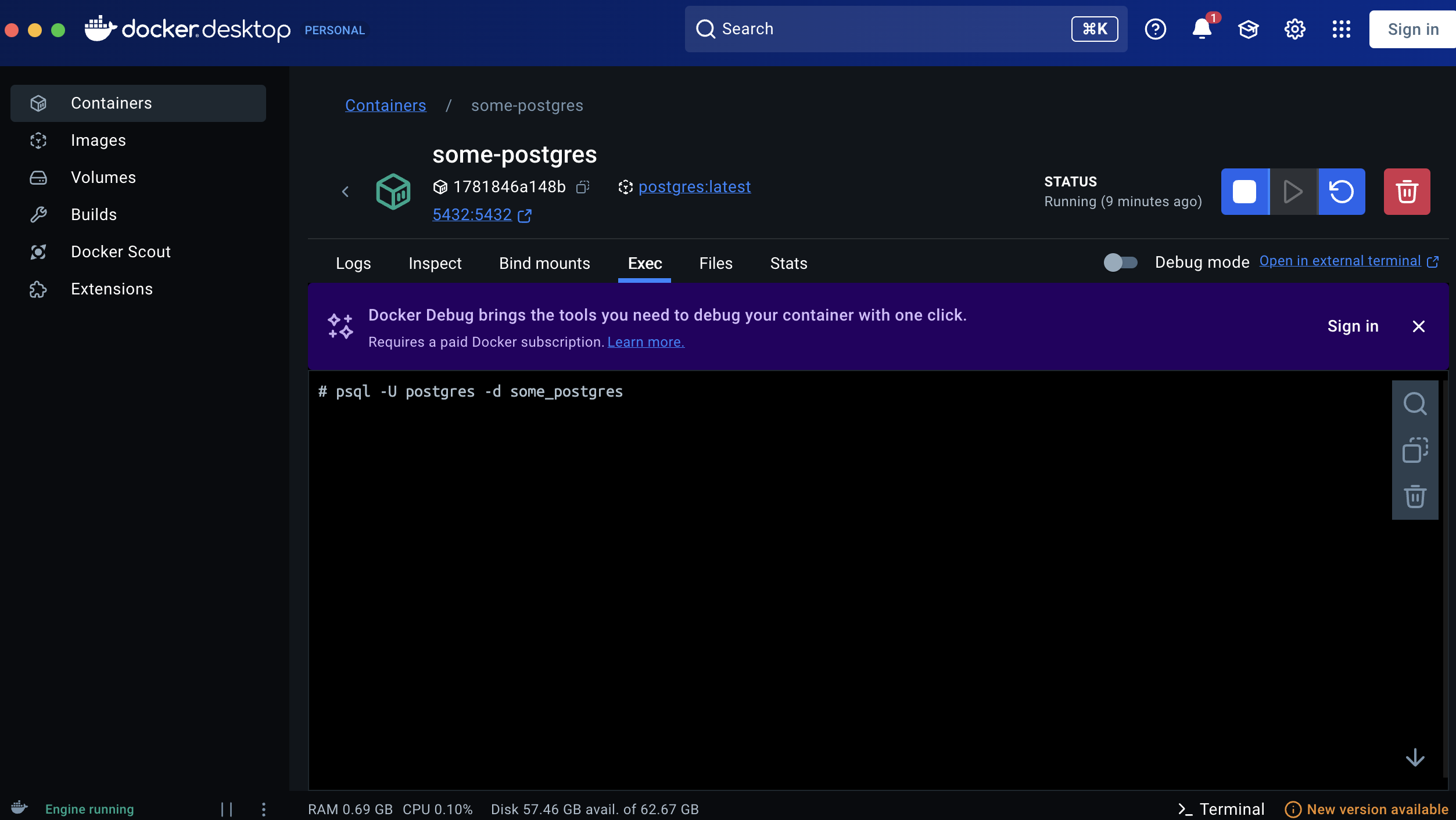
or you can do this via the command line docker exec -it some-postgres psql -U postgres -d some_postgres
# Enable extension
CREATE EXTENSION IF NOT EXISTS pg_trgm;10. Create Management Command to Populate Data
I used AI to create dogs/management/commands/populate_breeds.py to seed the database with 100+ dog breeds. This command:
python manage.py populate_breedsNow logging back into the database we can see 100 of results SELECT name FROM dogs_dogbreed;
11. Indexing:
Now we can generate the GIN index. Before you run this take a look at the RAM usage of the container using docker stats some-postgres before and after and you will see the indexing taking up more RAM space.
Let's go ahead log back into the database and run:
CREATE INDEX idx_items_name_trgm
ON dogs_dogbreed USING gin (name gin_trgm_ops);11. Testing the end points:
This step can not be understated. With AI and accelerated coding this is crucial to successful software. You should create tests and run them every time before pushing to staging or prod. In this case I'm not setting up CI/CD or even basic integration tests, so I will just use curl commands.
curl "http://localhost:8000/api/breeds/" # will return all the breeds
curl "http://localhost:8000/api/breeds/?search=mal"\ # will return a few breeds matchingFrontend Setup
1. Create React App with Vite
cd react_frontend
npm create vite@latest .
npm install2. Install Additional Dependencies
npm install tailwindcss @tailwindcss/vite3. Configure Tailwind CSS
In vite.config.js:
import { defineConfig } from "vite";
import react from "@vitejs/plugin-react";
import tailwindcss from "@tailwindcss/vite";
export default defineConfig({
plugins: [react(), tailwindcss()],
});In src/index.css:
@import "tailwindcss";4. Implement Live Search Component
In src/App.jsx, we created a component with:
State Management:
breeds: Stores search resultssearch: Current search querylastSearchTime: Throttles API calls
Debouncing: Uses a time-based throttle (100ms) to limit API calls:
useEffect(() => {
const currentTime = Date.now();
if (currentTime - lastSearchTime < 100) {
return;
}
setLastSearchTime(currentTime);
fetch(`http://localhost:8000/api/breeds/?search=${search}`)
.then((response) => response.json())
.then((data) => {
setBreeds(data);
});
}, [search]);Note
for debouncing there is another library you can use from lodash, but keep in mind lodash is a massive bundle that will slow load times and you can easily implement the same thing with this code
Conclusion
Now we have an awesome live search! You can use this anywhere you have searching on your website for a snappy experience. I have used this with large data sets (10,000+) which felt instant!
Future Enhancements
Potential improvements:
- Loading states: Show loading indicator during search giving user feedback if network connection is slow.
- Rate Limiting: Prevent DoS attacks against your endpoint.
- Error handling: Handle API errors gracefully on the frontend and provide usful error message on the backend.
- Pagination: For large result sets pagination may be necessary.
- Search highlighting: Highlight matching text in results (a cool frontend trick to give user insights into why the results show up)
- Multi-field search: Search across description and temperament fields.
- Filters: Add additonal filters for size, exercise needs, etc, amking this much more useful.